Since the first week of April 2022 I have (finally!) changed my company car from
a plug-in hybrid to a fully electic car. My new ride, for the next two years, is
a
BMW i4 M50 in Aventurine Red metallic.
An ellegant car with very deep and
memorable color, insanely powerful (544 hp/795 Nm), sub-4 second 0-100 km/h, large
84 kWh battery (80 kWh usable), charging up to 210 kW, top speed of 225 km/h
and also very efficient (which came out best in this trip) with WLTP range of 510 km
and
EVDB real range of 435 km. The car
also has performance tyres (Hankook Ventus S1 evo3 245/45R18 100Y XL in front and
255/45R18 103Y XL in rear all at recommended 2.5 bar) that have reduced efficiency.
So I wanted to document and describe how was it for me to travel ~2000 km (one way)
with this, electric, car from south of Germany to north of Latvia. I have done
this trip many times before since I live in Germany now and travel back to my
relatives in Latvia 1-2 times per year. This was the first time I made this trip in
an electric car. And as this trip includes both travelling in Germany (where BEV
infrastructure is best in the world) and across Eastern/Northen Europe, I believe
that this can be interesting to a few people out there.
Normally when I travelled this trip with a gasoline/diesel car I would normally drive
for two days with an intermediate stop somewhere around Warsaw with about 12 hours
of travel time in each day. This would normally include a couple bathroom stops in each
day, at least one longer lunch stop and 3-4 refueling stops on top of that. Normally
this would use at least 6 liters of fuel per 100 km on average with total usage of about
270 liters for the whole trip (or about 540 just in fuel costs, nowadays). My
(personal) quirk is that both fuel and recharging of my (business) car
inside Germany
is actually paid by my
employer, so it is useful
for me to charge up (or fill up) at the last station in Gemany before driving on.
The plan for this trip was made in a similar way as when travelling with a gasoline car:
travelling as fast as possible on German Autobahn network to last chargin stop on the A4
near G rlitz, there charging up as much as reasonable and then travelling to a hotel
in Warsaw, charging there overnight and travelling north towards Ionity chargers in
Lithuania from where reaching the final target in north of Latvia should be possible.
How did this plan meet the reality?
Travelling inside Germany with an electric car was basically perfect. The most efficient
way would involve driving fast and hard with top speed of even 180 km/h (where possible
due to speed limits and traffic). BMW i4 is very efficient at high speeds with consumption
maxing out at 28 kWh/100km when you actually drive at this speed all the time. In real
situation in this trip we saw consumption of 20.8-22.2 kWh/100km in the first legs of the trip.
The more traffic there is, the more speed limits and roadworks, the lower is the average
speed and also the lower the consumption. With this kind of consumption we could comfortably
drive 2 hours as fast as we could and then pick any fast charger along the route and in
26 minutes at a charger (50 kWh charged total) we'd be ready to drive for another 2 hours.
This lines up very well with recommended rest stops for biological reasons (bathroom, water
or coffee, a bit of movement to get blood circulating) and very close to what I had to do
anyway with a gasoline car. With a gasoline car I had to refuel first, then park, then go to
bathroom and so on. With an electric car I can do all of that
while the car is charging and
in the end the total time for a stop is very similar. Also not that there was a crazy heat
wave going on and temperature outside was at about 34C minimum the whole day and hitting
40C at one point of the trip, so a lot of power was used for cooling. The car has a heat pump
standard, but it still was working hard to keep us cool in the sun.
The car was able to plan a charging route with all the charging stops required and had all
the good options (like multiple intermediate stops) that many other cars (hi Tesla) and
mobile apps (hi Google and Apple) do
not have yet. There are a couple bugs with charging
route and display of current route guidance, those are already fixed and will be delivered
with over the air update with July 2022 update. Another good alterantive is the ABRP (A
Better Route Planner) that was specifically designed for electric car routing along the
best route for charging. Most phone apps (like Google Maps) have no idea about your specific
electric car - it has no idea about the battery capacity, charging curve and is missing key
live data as well - what is the current consumption and remaining energy in the battery. ABRP
is different - it has data and profiles for almost all electric cars and can also be linked to
live vehicle data, either via a OBD dongle or via a new Tronity cloud service. Tronity reads
data from vehicle-specific cloud service, such as MyBMW service, saves it, tracks history and
also re-transmits it to ABRP for live navigation planning. ABRP allows for options and settings
that no car or app offers, for example, saying that you want to stop at a particular place for
an hour or until battery is charged to 90%, or saying that you have specific charging cards and
would only want to stop at chargers that support those. Both the car and the ABRP also support
alternate routes even with multiple intermediate stops. In comparison, route planning by Google
Maps or Apple Maps or Waze or even Tesla does not really come close.
After charging up in the last German fast charger, a more interesting part of the trip started.
In Poland the density of high performance chargers (HPC) is much lower than in Germany. There are
many chargers (west of Warsaw), but vast majority of them are (relatively) slow 50kW chargers.
And that is a difference between putting 50kWh into the car in 23-26 minutes or in 60 minutes. It
does not seem too much, but the key bit here is that for 20 minutes there is easy to find stuff
that should be done anyway, but after that you are done and you are just waiting for the car and
if that takes 4 more minutes or 40 more minutes is a big, perceptual, difference. So using
HPC is much, much preferable. So we put in the Ionity charger near Lodz as our intermediate target
and the car suggested an intermediate stop at a Greenway charger by Katy Wroclawskie. The location
is a bit weird - it has 4 charging stations with 150 kW each. The weird bits are that each station
has two CCS connectors, but only one parking place (and the connectors share power, so if two cars
were to connect, each would get half power). Also from the front of the location one can only see
two stations, the otehr two are semi-hidden around a corner. We actually missed them on the way
to Latvia and one person actually waited for the charger behind us for about 10 minutes. We only
discovered the other two stations on the way back. With slower speeds in Poland the consumption
goes down to 18 kWh/100km which translates to now up to 3 hours driving between stops.
At the end of the first day we drove istarting from Ulm from 9:30 in the morning until about 23:00 in the evening with
total distance of about 1100 km, 5 charging stops, starting with 92% battery, charging for
26 min (50 kWh), 33 min (57 kWh + lunch), 17 min (23 kWh), 12 min (17 kWh) and 13 min (37 kW).
In the last two chargers you can see the difference between a good and fast 150 kW charger at high
battery charge level and a
really fast Ionity charger at low battery charge level, which makes
charging faster still.
Arriving to hotel with 23% of battery. Overnight the car charged from a Porsche Destination
Charger to 87% (57 kWh). That was a bit less than I would expect from a full power 11kW charger,
but good enough. Hotels should really install 11kW Type2 chargers for their guests, it is a really
significant bonus that drives more clients to you.
The road between Warsaw and Kaunas is the most difficult part of the trip for both driving itself
and also for charging. For driving the problem is that there
will be a new highway going from
Warsaw to Lithuanian border, but it is actually not
fully ready yet. So parts of the way one drives
on the new, great and wide highway and parts of the way one drives on temporary roads or on old
single lane undivided roads. And the most annoying part is navigating between parts as signs are
not always clear and the maps are either too old or too new. Some maps do not have the new roads and
others have on the roads that have not been actually build or opened to traffic yet. It's really easy
to loose ones way and take a significant detour. As far as charging goes, basically there is only
the slow 50 kW chargers between Warsaw and Kaunas (for now). We chose to charge on the last charger
in Poland, by Suwalki Kaufland. That was not a good idea - there is only one 50 kW CCS and many people
decide the same, so there can be a wait. We had to wait 17 minutes before we could charge for
30 more minutes just to get 18 kWh into the battery. Not the best use of time. On the way back we chose
a different charger in Lomza where would have a relaxed dinner while the car was charging. That
was far more relaxing and a better use of time.
We also tried charging at an Orlen charger that was not recommended by our car and we found out why.
Unlike
all other chargers during our entire trip, this charger did not accept our universal BMW Charging
RFID card. Instead it demanded that we download their own Orlen app and register there. The app is only
available in some countries (and not in others) and on iPhone it is only available in Polish. That is a
bad exception to the rule and a bad example. This is also how most charging works in USA. Here in Europe
that is not normal. The normal is to use a charging card - either provided from the car maker or from
another supplier (like PlugSufring or Maingau Energy). The providers then make roaming arrangements with
all the charging networks, so the cards just work everywhere. In the end the user gets the prices and the
bills from their card provider as a single monthly bill. This also saves all any credit card charges for
the user. Having a clear, separate RFID card also means that one can easily choose how to pay for each
charging session. For example, I have a corporate RFID card that my company pays for (for charging in
Germany) and a private BMW Charging card that I am paying myself for (for charging abroad). Having the
car itself authenticate direct with the charger (like Tesla does) removes the option to choose how to pay.
Having each charge network have to use their own app or token bring too much chaos and takes too much setup.
The optimum is having one card that works everywhere and having the option to have additional card
or cards for specific purposes.
Reaching Ionity chargers in Lithuania is again a breath of fresh air - 20-24 minutes to charge 50 kWh is
as expected. One can charge on the first Ionity just enough to reach the next one and then on the second
charger one can charge up enough to either reach the Ionity charger in Adazi or the final target in Latvia.
There is a huge number of CSDD (Road Traffic and Safety Directorate) managed chargers all over Latvia,
but they are 50 kW chargers. Good enough for local travel, but not great for long distance trips. BMW i4
charges at over 50 kW on a HPC even at over 90% battery state of charge (SoC). This means that it is always
faster to charge up in a HPC than in a 50 kW charger, if that is at all possible. We also tested the CSDD
chargers - they worked without any issues. One could pay with the BMW Charging RFID card, one could use
the CSDD e-mobi app or token and one could also use Mobilly - an app that you can use in Latvia for
everything from parking to public transport tickets or museums or car washes.
We managed to reach our final destination near Aluksne with 17% range remaining after just 3 charging stops:
17+30 min (18 kWh), 24 min (48 kWh), 28 min (36 kWh). Last stop we charged to 90% which took a few extra
minutes that would have been optimal.
For travel around in Latvia we were charging at our target farmhouse from a normal 3 kW Schuko EU socket.
That is very slow. We charged for 33 hours and went from 17% to 94%, so not really full. That was perfectly
fine for our purposes. We easily reached Riga, drove to the sea and then back to Aluksne with 8% still
in reserve and started charging again for the next trip. If it were required to drive around more and charge
faster, we could have used the normal 3-phase 440V connection in the farmhouse to have a red CEE 16A plug
installed (same as people use for welders). BMW i4 comes standard with a new BMW Flexible Fast Charger
that has changable socket adapters. It comes by default with a Schucko connector in Europe, but for 90
one can buy an adapter for blue CEE plug (3.7 kW) or red CEE 16A or 32A plugs (11 kW). Some public charging
stations in France actually use the blue CEE plugs instead of more common Type2 electric car charging stations.
The CEE plugs are also common in camping parking places.
On the way back the long distance BEV travel was already well understood and did not cause us any problem. From
our destination we could easily reach the first Ionity in Lithuania, on the Panevezhis bypass road where
in just 8 minutes we got 19 kWh and were ready to drive on to Kaunas, there a longer 32 minute stop before
the charging desert of Suwalki Gap that gave us 52 kWh to 90%. That brought us to a shopping mall in Lomzha
where we had some food and charged up 39 kWh in lazy 50 minutes. That was enough to bring us to our return hotel
for the night - Hotel 500W in Strykow by Lodz that has a 50kW charger on site, while we were having late
dinner and preparing for sleep, the car easily recharged to full (71 kWh in 95 minutes), so I just moved
it from charger to a parking spot just before going to sleep. Really easy and well flowing day.
Second day back went even better as we just needed an 18 minute stop at the same Katy Wroclawskie charger
as before to get 22 kWh and that was enough to get back to Germany. After that we were again flying on the
Autobahn and charging as needed, 15 min (31 kWh), 23 min (48 kWh) and 31 min (54 kWh + food). We started the
day on about 9:40 and were home at 21:40 after driving just over 1000 km on that day. So less than 12 hours
for 1000 km travelled, including all charging, bio stops, food and some traffic jams as well. Not bad.
Now let's take a look at all the apps and data connections that a technically minded customer can have
for their car. Architecturally the car is a network of computers by itself, but it is very secured and
normally people do not have any direct access. However, once you log in into the car with your BMW account
the car gets your profile info and preferences (seat settings, navigation favorites, ...) and the car then
also can start sending information to the BMW backend about its status. This information is then available
to the user over multiple different channels. There is no separate channel for each of those data flow.
The data only goes once to the backend and then all other communication of apps happens with the backend.
First of all the
MyBMW app.
This is the go-to for everything about the car - seeing its current status and location (when not driving),
sending commands to the car (lock, unlock, flash lights, pre-condition, ...) and also monitor and control
charging processes. You can also plan a route or destination in the app in advance and then just send it over
to the car so it already knows where to drive to when you get to the car. This can also integrate with calendar
entries, if you have locations for appointments, for example. This also shows full charging history and
allows a very easy
export of that data, here I exported all charging sessions from June and then
trimmed it back to only sessions relevant to the trip and cut off some design elements to have the data more
visible.
So one can very easily see when and where we were charging, how much power we got at each spot and
(if you set prices for locations) can even show costs.
I've already mentioned the Tronity service and its ABRP integration, but it also saves the information that
it gets from the car and gathers that data over time. It has nice aspects, like showing the
driven routes
on a map, having ways to do business trip accounting and having good calendar view. Sadly it does not correctly
capture the data for
charging sessions (the amounts are incorrect).
Update: after talking to Tronity support, it looks like the bug was in the incorrect value for the usable
battery capacity for my car. They will look into getting th eright values there by default, but as a workaround
one can edit their car in their system (after at least one charging session) and directly set the expected
battery capacity (usable) in the car properties on the Tronity web portal settings.
One other fun way to see data from your BMW is using the
BMW integration in Home Assistant.
This brings the car as a device in your own smart home. You can read all the variables from the car current status
(and Home Asisstant makes
cute historical charts) and you can even see
interesting trends, for example for
remaining range shows much
higher value in Latvia as its prediction is adapted to Latvian road speeds and during the trip it adapts to Polish
and then to German road speeds and thus to higher consumption and thus lower maximum predicted remaining range.
Having the car attached to the Home Assistant also allows you to attach the car to automations, both as data and event
source (like detecting when car enters the "Home" zone) and also as target, so you could flash car lights or even
unlock or lock it when certain conditions are met.
So, what in the end was the most important thing - cost of the trip? In total we charged up 863 kWh, so that would
normally cost one about 290 , which is close to half what this trip would have costed with a gasoline car. Out of
that 279 kWh in Germany (paid by my employer) and 154 kWh in the farmhouse (paid by our wonderful relatives :D) so
in the end the charging that I actually need to pay adds up to 430 kWh or about 150 . Typically, it took about 400
in fuel that I had to pay to get to Latvia and back. The difference is really nice!
In the end I believe that there are three different ways of charging:
-
incidental charging - this is wast majority of charging in the normal day-to-day life. The car gets charged when
and where it is convinient to do so along the way. If we go to a movie or a shop and there is a chance to leave
the car at a charger, then it can charge up. Works really well, does not take extra time for charging from us.
-
fast charging - charging up at a HPC during optimal charging conditions - from relatively low level to no more
than 70-80% while you are still doing all the normal things one would do in a quick stop in a long travel
process: bio things, cleaning the windscreen, getting a coffee or a snack.
-
necessary charging - charging from a whatever charger is available just enough to be able to reach the next
destination or the next fast charger.
The last category is the only one that is really annoying and should be avoided at all costs. Even by shifting
your plans so that you find something else useful to do while necessary charging is happening and thus, at least
partially, shifting it over to incidental charging category. Then you are no longer just waiting for the car,
you are doing something else and the car magically is charged up again.
And when one does that, then travelling with an electric car becomes no more annoying than travelling with
a gasoline car. Having more breaks in a trip is a good thing and makes the trips actually easier and less
stressfull - I was more relaxed during and after this trip than during previous trips. Having the car air
conditioning always be on, even when stopped, was a godsend in the insane heat wave of 30C-38C that we were
driving trough.
Final stats: 4425 km driven in the trip. Average consumption: 18.7 kWh/100km. Time driving: 2 days and 3 hours.
Car regened 152 kWh. Charging stations recharged 863 kWh.
Questions? You can use
this i4talk forum thread or
this Twitter thread to ask them to me.
 Update on 2023-03-23: thanks to Daniel Roschka for mentioning the Mandos and TPM approaches, which might be better alternatives, depending on your options and needs. Peter Palfrader furthermore pointed me towards clevis-initramfs and tang.
A customer of mine runs dedicated servers inside a foreign data-center, remote hands only. In such an environment you might need a disk replacement because you need bigger or faster disks, though also a disk might (start to) fail and you need a replacement. One has to be prepared for such a scenario, but fully wiping your used disk then might not always be an option, especially once disks (start to) fail. On the other hand you don t want to end up with (partial) data on your disk handed over to someone unexpected.
By encrypting the data on your disks upfront you can prevent against this scenario. But if you have a fleet of servers you might not want to manually jump on servers during boot and unlock crypto volumes manually. It s especially annoying if it s about the root filesystem where a solution like dropbear-initramfs needs to be used for remote access during initramfs boot stage. So my task for the customer was to adjust encrypted LUKS devices such that no one needs to manually unlock the encrypted device during server boot (with some specific assumptions about possible attack vectors one has to live with, see the disclaimer at the end).
The documentation about this use-case was rather inconsistent, especially because special rules apply for the root filesystem (no key file usage), we see different behavior between what s supported by systemd (hello key file again), initramfs-tools and dracut, not to mention the changes between different distributions. Since tests with this tend to be rather annoying (better make sure to have a Grml live system available :)), I m hereby documenting what worked for us (Debian/bullseye with initramfs-tools and cryptsetup-initramfs).
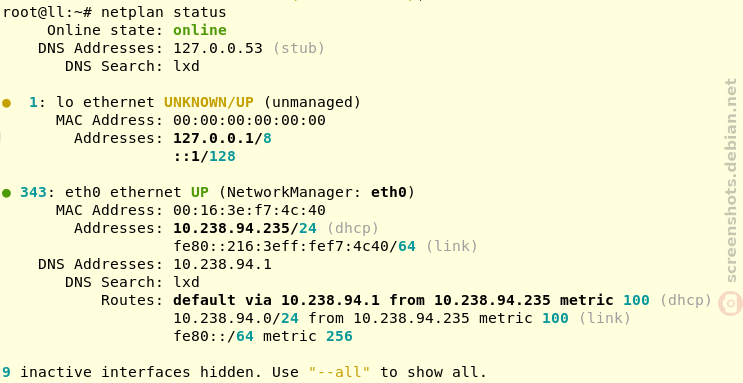
The system was installed with LVM on-top of an encrypted Software-RAID device, only the /boot partition is unencrypted. But even if you don t use Software-RAID nor LVM the same instructions apply. The system looks like this:
Update on 2023-03-23: thanks to Daniel Roschka for mentioning the Mandos and TPM approaches, which might be better alternatives, depending on your options and needs. Peter Palfrader furthermore pointed me towards clevis-initramfs and tang.
A customer of mine runs dedicated servers inside a foreign data-center, remote hands only. In such an environment you might need a disk replacement because you need bigger or faster disks, though also a disk might (start to) fail and you need a replacement. One has to be prepared for such a scenario, but fully wiping your used disk then might not always be an option, especially once disks (start to) fail. On the other hand you don t want to end up with (partial) data on your disk handed over to someone unexpected.
By encrypting the data on your disks upfront you can prevent against this scenario. But if you have a fleet of servers you might not want to manually jump on servers during boot and unlock crypto volumes manually. It s especially annoying if it s about the root filesystem where a solution like dropbear-initramfs needs to be used for remote access during initramfs boot stage. So my task for the customer was to adjust encrypted LUKS devices such that no one needs to manually unlock the encrypted device during server boot (with some specific assumptions about possible attack vectors one has to live with, see the disclaimer at the end).
The documentation about this use-case was rather inconsistent, especially because special rules apply for the root filesystem (no key file usage), we see different behavior between what s supported by systemd (hello key file again), initramfs-tools and dracut, not to mention the changes between different distributions. Since tests with this tend to be rather annoying (better make sure to have a Grml live system available :)), I m hereby documenting what worked for us (Debian/bullseye with initramfs-tools and cryptsetup-initramfs).
The system was installed with LVM on-top of an encrypted Software-RAID device, only the /boot partition is unencrypted. But even if you don t use Software-RAID nor LVM the same instructions apply. The system looks like this:











 I had bought a Thinkpad E470 laptop back in 2018 which was lying unused for
quite some time. Recently when I wanted to use it, I found that the keyboard is
not working, especially some keys and after some time the laptop will hang in
Lenovo boot screen. I came back to Bangalore almost after 2 years from my
hometown (WFH due to Covid) and thought it was the right time to get my laptop
back to normal working state. After getting the keyboard replaced I noticed that
1TB HDD is no longer fast enough for my taste!. I've to admit I never thought I
would start disliking HDD so quickly thanks to modern SSD based work laptops. So
as a second upgrade I got the HDD removed from my laptop and got a 240G SSD.
Yeah I know its reduction from my original size but I intend to continue using
my old HDD via USB SATA enclosure as an external HDD which can house the extra
data which I need to save.
So now that I've a SSD I need to install Debian Unstable again on it and this is
where I tried something new. My colleague (name redacted on request) suggested
to me use GRML live CD and install Debian via debootstrap. And after giving a
thought I decided to try this out. Some reason for going ahead with this are
listed below
I had bought a Thinkpad E470 laptop back in 2018 which was lying unused for
quite some time. Recently when I wanted to use it, I found that the keyboard is
not working, especially some keys and after some time the laptop will hang in
Lenovo boot screen. I came back to Bangalore almost after 2 years from my
hometown (WFH due to Covid) and thought it was the right time to get my laptop
back to normal working state. After getting the keyboard replaced I noticed that
1TB HDD is no longer fast enough for my taste!. I've to admit I never thought I
would start disliking HDD so quickly thanks to modern SSD based work laptops. So
as a second upgrade I got the HDD removed from my laptop and got a 240G SSD.
Yeah I know its reduction from my original size but I intend to continue using
my old HDD via USB SATA enclosure as an external HDD which can house the extra
data which I need to save.
So now that I've a SSD I need to install Debian Unstable again on it and this is
where I tried something new. My colleague (name redacted on request) suggested
to me use GRML live CD and install Debian via debootstrap. And after giving a
thought I decided to try this out. Some reason for going ahead with this are
listed below
 youngest LUKS user I know...
So I'm in Berlin currently to attend the fourth
youngest LUKS user I know...
So I'm in Berlin currently to attend the fourth 
 My work computer runs Debian 11 bullseye (the current stable release) in a mechanical 500GB disk, and I was provided with a new SDD disk but its size was 480 GB. So I had to shrink my partitions before copying the data to the new disk. It turned out to be a bit difficult because my main partition was encrypted.
I write here how I did, maybe there are other simpler ways but I couldn t find them.
References:
My work computer runs Debian 11 bullseye (the current stable release) in a mechanical 500GB disk, and I was provided with a new SDD disk but its size was 480 GB. So I had to shrink my partitions before copying the data to the new disk. It turned out to be a bit difficult because my main partition was encrypted.
I write here how I did, maybe there are other simpler ways but I couldn t find them.
References:
 (Well, the actual process was not so smooth but after several tries and errors and searching for help I managed to get the needed commands to make my system boot from the new disk).
(Well, the actual process was not so smooth but after several tries and errors and searching for help I managed to get the needed commands to make my system boot from the new disk).


















 The following contributors got their Debian Developer accounts in the last two months:
The following contributors got their Debian Developer accounts in the last two months:
 Just as
Just as 